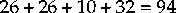 ; the
; the 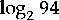 is
6.5546 the ceiling is 7 bits.
Usually an extra bit is added to make 8 bits.
This is done because 8 is a power of two, and as you probably are
already beginning to feel, having things organized in powers of two
is convenient.
is
6.5546 the ceiling is 7 bits.
Usually an extra bit is added to make 8 bits.
This is done because 8 is a power of two, and as you probably are
already beginning to feel, having things organized in powers of two
is convenient.
The last sections gave you some tools and some ideas about how many bits are needed to represent information inside a computer and how numbers and logic formulas are represented and computed.
If you have a western alphabet with 26 lower-case characters, 26 upper-case
characters, 10 numbers, and 32 special characters in which each character
could be presumed to be equally likely, how many bits do you need to
represent the characters?
Thus ; the is
6.5546 the ceiling is 7 bits.
Usually an extra bit is added to make 8 bits.
This is done because 8 is a power of two, and as you probably are
already beginning to feel, having things organized in powers of two
is convenient.
The 8 bits that make up a character are often called a byte. A byte can also be thought of as a little unsigned integer, with values between 0 and 255. Using this idea one can assign a character to an equivalent small integer value. A character to integer table that characterizes a machine is called its character set. IBM main frame computers use the EBCDIC character set. EBCDIC is usually pronounced like `epsidick' and stands for Extended Binary Coded Decimal Interchange Code. Oriental languages require thousands of characters and they have their own standards with 16-bit characters.
Most small computers and many large ones that are not IBM use the
ASCII character set, including the Macintosh, the IBM PC, Sun workstations,
and many others.
ASCII is usually pronounced `as-ski' and it stands for American Standard Code
for Information Interchange.
The table below is a standard map of the 7-bit ASCII character set.
It lists octal, decimal, and hexadecimal equivalents for each character.
Note all character values are the same for all the tables, only the
representation of the numeric position varies.
The three tables are given only to ease access from some predetermined
number base.
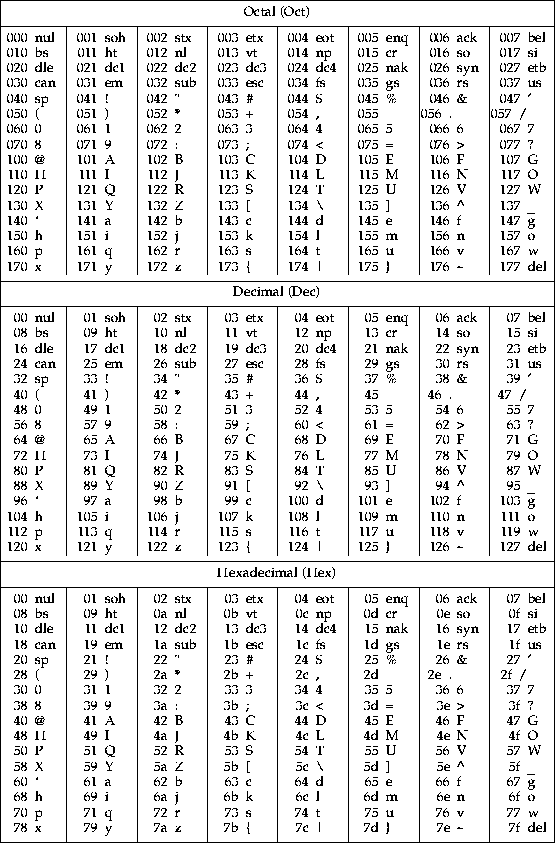
Characters inherit properties from their associated number in the character code. So depending on the position of characters the numeric relationships change. In both the lower and upper case sequences a letter later in the alphabet is greater. So `n' < `p', and `N' < `P'. The numeric digits are listed in increasing order and the difference between any two digits is the difference in the value of the digits. So if $x$ is a character that is a numeric digit then $x~-$ `0' is an integer value representing the value of $x$.
In ASCII small letters are always greater than capital letters.
That is one can say that `Z' < `a'.
However this relationship is not consistent across all character codes.
In EBCDIC the alphabet maintains the numeric relationships described
above, but it is not compact.
Internal to the alphabet are placed special characters.
Do not write programs that depend on the value of differences
between alphabetic characters.
One place where this convention is commonly broken
in hexadecimal input/output routines.
The standard hex alphabetic digits, A through F in both character sets
are compact.
This is handy to know if you want to write a program to input hex numbers
and want it to work on a wide variety of computers.