Prior Page
Next Page
This Chapter
Prior Chapter
Mathematical Randomness
There is a long and complex history to the idea of randomness
in mathematical thought.
That means that there is also an extensive literature about these
ideas.
For the limited purposes of creating random sequences of numbers
on a computer, only some simple properties of randomness need
to be understood.
Mathematicians model fortune by stating requirements for a sequence
of numbers.
These requirements have been approached in several ways.
The next several paragraphs works toward a semi-formal definition
of randomness that is, at least in spirit, mathematical.
The ideas behind the formal definition are far more important
than the formalism itself, although without the formalism
the precision of definition will be lacking.
As a first try: take the idea of unpredictability and use it to
define randomness.
To be a random number sequence, the numbers in the sequence must
be generated as if they were independent draws from a well mixed urn
where each number is represented once in the urn.
The idea of randomness comes from drawing a number from the urn.
You write down that number, replace the token in the urn, mix the urn
well and draw another number.
This idea of unpredictability and equal probability is embodied in
the random process.
This definition has advantages because it makes clear what a finite
random string is; it is a series of numbers derived from the process.
It also makes clear that if the process that you are doing can be mapped
back onto the model process then your process also produces random numbers.
So for example if I count the time between atomic events, say the
ticks on a Geiger counter, then I need to show some transformation
that makes this equivalent to drawing balls from an urn.
If I do this, I know that I'm also generating random numbers by
my new method.
But mathematicians are not happy with processes, they prefer an abstract
specification.
To make our definition more mathematical, we must move away from
describing the process toward specifying the result.
So as a second try mathematicians might like more general language for
the definition of random sequence.
The importance of returning the token and mixing the urn is to make each
draw independent of all other draws.
In this way numbers always have the same chance of occurring.
We can use the idea of independence and equal probability
as the basis for a second definition.
A random sequence is one in which each number in the sequence
is independent and equally probable.
Now independence hasn't been pinned down well by the second definition.
We have a feeling for it from independent draws from the urn.
These draws are unrelated to any functional dependence between the numbers.
So one could conceive of an argument that any calculation that generated
numbers would make them depend on one another.
Therefore this definition, by its nature, excludes computing a random sequence.
Secondly it has moved a little bit away from unpredictability.
The drawing from an urn, was the specification of an unpredictable process,
now the random number generator is free to be any process as long
as the choices provide independent numbers.
Are there non-random processes that will generate a series of independent
numbers?
I don't know, but the definition says nothing about it either.
How do I prove the independence of the numbers without knowing how they
are produced (or chosen)?
I don't know that either, because there is no good definition.
One could try abstracting this definition even further to try work free of
`independence', which will be hard to define in any case.
So for try three at a mathematical definition we will use just the
resulting distribution of numbers that occurs when one selects
numbers independently.
Assume we can characterize what distribution of numbers any series of
random draws would produce as a sequence and then characterize this
distribution.
In a infinite sequence any finite sub-sequence (of any lenght)
will be repeated an infinite number of times.
You will never be able to tell by looking at the next number
which of the sub-sequences are repeating, since the probability of
the next number is equal to any other possible number.
We can call this complete random distribution
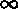 -distributed.
Now our third definition might read:
An infinite random sequence is -distributed, in
which any possible finite sub-sequence of numbers is uniformly
distributed.
-distributed.
Now our third definition might read:
An infinite random sequence is -distributed, in
which any possible finite sub-sequence of numbers is uniformly
distributed.
This third definition is more abstract,
but it is also farther from what we usually mean by random.
Note that the unpredictability of luck is now completely gone,
the distribution is all that counts.
This definition avoids specifying the process of independence and replaces it
with the specification of
-distributions.
This distribution specification works only in the limit as the
sequence is viewed as infinite.
This provides little help for identifying or generating sequences
in a finite world.
It does seem to have cleared the way to generate random sequences
by machine because the independence constraint is gone, only the
distribution counts.
If a machine algorithm can distribute numbers properly then it fulfills
the definition.
However the mathematical definition of the distribution is
so strong that any sub-sequence that continually repeats is not random.
Any finite number of repeats of any finite section of the sequence is fine,
but no section can repeat continually.
Any finite computer program that generates randoms will eventually
run out of energy and either stop or repeat.
If it stops or repeats the distribution will not be
-distributed.
Thus, this mathematical definition also excludes any finite computation
that generates apparently random numbers from being a random
number generator.
But how about finite sequences that would be infinite if one could
compute them?
Ones that are long enough and have the right distribution but we
are only looking a finite segment of the eventual sequence,
provided of course that there was enough memory to keep computing them?
Let's look at an example.
|
|
38 29 39 29 39 56 01 56 34...
|
|
Now this is a `computable' sequence; it never ends,
and can be computed as far as one wishes.
It always produces numbers between 0 and 99,
and presumably it fulfills the -distributional
mathematical definition of random.
This has never been proven, but it is a good conjecture.
This would be for all intents a computable random sequence.
This sequence suffers one major defect, it is predictable.
The computation is highly regular, and once recognized it holds no
surprises.
It certainly does not satisfy the real world (unpredictable) definition
of random at all.
So this sequence is presumably random by our third definition,
not clearly random or non-random by the second definition,
and not random at all by the first definition, since its generator
can't be transformed into random urn choices.
I'll give ten New Zealand dollars to the first 1995 CS105 student that
discovers the pattern behind the sequence, and finds and reports it to
me correctly.
If you don't know the rules behind the sequence generator then
the next number could be anything -- for you it is a random sequence.
If you know the secret, it is anything but random.
There is also an interesting definition of relative randomness based
on the size of the minimal sized program that can generate a given
random sequence as a measure of its randomness.
Terminating programs create finite sequences.
Non-terminating programs create infinite sequences.
Thus the minimum non-terminating program, which generates the
mysterious sequence, would be small (in absolute terms)
and so the resulting string is somewhat random but not as random
as one that took a larger minimal program to create it.
This implies that the best random strings are infinitely long.
Since any finite program will eventually repeat,
infinitely long random sequences require an infinitely long program
to produce them.
Not a promising result for an engineer who wishes to generate
the best possible random sequences with the smallest possible
code in a finitely limited world.
More to a practical point is what are the implications of mathematical
randomness and how close can we come to unpredictability in an algorithm
so that will allow a computer to produce suitable random sequences.
It can be shown in mathematical randomness (any of the three definitions)
that any sequence of n numbers is equi-probable.
Assume one has a random sequence of numbers where each number is
between 0 and 999,999,999.
This implies that the following three ten number sequences
and
and
|
|
33098860, 682003184,443887686, 65512535, 231053651,
|
|
|
|
792705375, 348526243, 67660953, 392913323, 257117505
|
|
are all equally probable.
This doesn't seem to make much intuitive sense, nor does it seem
to fit with one's experience.
The reason of course is that for the first two sequences you can
feel your way to predicting the next one.
You are pretty sure you know what comes next.
Whereas the last sequence convinces you that you have no idea what is coming.
But your feelings were misleading you if the draws were really independent.
On the other hand the likelihood of getting one in any particular sequence
of ten numbers was extraordinarily low ... 1 in 1090.
Changes in base will not retain randomness.
For example a decimal random sequence of single digits changed to binary
will not have equally probable ones and zeros.
It is easy to see why... think about it.
But one obvious property of mathematical random sequences is that selecting
sets of bits from a random bit sequence will retain the random properties.
And thus one random sequence can be transformed into another binary compatible
random sequence fairly easily.
One can also take a source of independent (partially random) bits
(in which the probability of a 1 bit is not ½) and make a true random
bit source by using bit pairs. Throw away all the 00 and 11 pairs;
make 10 pairs 1; make 01 pairs 0, the result will be a unbiased random
source.
Of course this method is pretty inefficient because it throws away a lot
of data, and after that it uses two bits for every one generated.
This simple trick was invented by our mathematician friend John von Neumann.
Other people have made much more complicated algorithms to do the same
thing which are much more efficient.
There are also methods for taking two partially random and unrelated
sources and producing an unbiased random source from them.
Can you figure out how?
Assume that the numbers in a random sequence are drawn from a compact range
of integers from 0 to 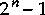 , where n is a positive integer!
Each number in the sequence will consist of exactly n binits.
If these binits are concatenated (including the leading zero binits)
the probability that in the resulting bit stream the next binit
will be a 1 is exactly ½.
This results in a continuous stream of random bits, because
there is exactly one bit per binit (from the information theory equations).
One can divide this binit sequence arbitrarily and create
an information source with any number of bits of output.
So this stream of random bits can be arbitrarily recoded
so it represents other sources.
, where n is a positive integer!
Each number in the sequence will consist of exactly n binits.
If these binits are concatenated (including the leading zero binits)
the probability that in the resulting bit stream the next binit
will be a 1 is exactly ½.
This results in a continuous stream of random bits, because
there is exactly one bit per binit (from the information theory equations).
One can divide this binit sequence arbitrarily and create
an information source with any number of bits of output.
So this stream of random bits can be arbitrarily recoded
so it represents other sources.
There is also some interesting mathematical work that suggests
that random strings are incompressible (in an information theory sense).
That is since every bit in a random bit stream is equally probable
no algorithm can be substituted for the bit stream, and every algorithm
that might try will take at least as many bits to represent as the bit
stream it is supposed to generate.
Some final points.
It has not been shown that unpredictability can not be quantified in a
clean mathematical sense.
A definition of random based on `mathematical unpredictability' could
provide better and cleaner properties than any of the models we
currently have.
It would also provide the basis for measurement and proof that
random number generation algorithms produce what they say they
produce in the real world.
Mathematicians have not had the last word in trying to grab the essence
of random and capturing it.
They realize the inadequacies of their own definitions and they will
keep trying to make them better.
But this survey should give you some feel for the idea of mathematical
randomness and the philosophical issues that swirl around it.
Prior Page
Next Page
This Chapter
Prior Chapter
Copyright © 1995 Robert Uzgalis. All Rights Reserved.
Contact: buz@cs.aukuni.ac.nz